Backpropagating Through My Career (Part 1)
Reflecting on 1.5 years as a ML and Computer Vision Research Engineer
In August of 2018, I started my role as a Research Software Engineer at IBM Research in Cambridge, MA. Going into the job, I didn’t have any idea that I would be where I am today. It’s hard to believe how much I’ve grown and learned since then. From going to my first CVPR (Computer Vision and Pattern Recognition Conference), to getting my work open sourced, I’ve gotten to do and experience so many things that I wouldn’t have thought I would get to do until later in my career.
Recently, I’ve been thinking back on everything that’s happened in the past year and a half, and wanted to take the chance to write out my thoughts, lessons I’ve learned, and things that I think I could do better or differently going forward.
As I started writing this, I realized that there is a lot to cover, so this is the first in a series of posts about my time working so far. For this post, I’m going to focus on talking about how I got where I am now, and the work that I’ve done in that time.
How I Got Here
Coming straight out of my undergraduate days at University of Florida (with a brief summer break), I started working in Cambridge at the beginning of August 2018. I came into the job with a good amount of knowledge of machine learning and computer vision from self study and research that I did during college.

I learned that most of my team was situated in Yorktown Heights, NY, so I mostly worked remote, aside from 1 teammate in the Cambridge office. Going into the job, I thought I would be mostly focusing on assisting my coworkers by building them tools to assist them in their research as well as helping out on projects in any ways that I could. These are definitely things I still do, but my role has significantly grown from when I first started. My team is comprised of mostly researchers, so they didn’t have a background in some of the modern software engineering practices there are today. In the time that I’ve been working, I’ve tried to help grow the skills of my teammates by teaching them some of the practices that I know and have learned myself in this time. Not everything sticks, but even a little bit of improvement in how they write their software can go a long way.
As time went on, I realized that a lot of work was needed on our system as a whole, especially when we received new requirements of being real time, and making our system run end to end. I took it upon myself to try to improve some of the parts of our system that needed to change in order to accomplish this. Since I was coming straight out of college, I had to learn a lot of system design and architecture through trial by fire. I spent days and weeks figuring out the best way to rework our system both from engineering and research perspectives.
After some time learning and deciding on what I needed to do, I ended up rebuilding our system from the ground up to better support these new requirements. With that, I was able to put into place some standards on how the system should be developed moving forward, which has alleviated some of the pains of the previous system which was being held together with digital duct tape.
What I do
In my day to day role, I am working with my team to participate in the DIVA Program, which is a government funded research project with the goal of pushing the state of the art in activity detection for extended videos. For instance, imagine having a CCTV camera feed for a parking lot, and you want to identify when and where a car pulls up and parks, or a person puts something in their trunk. We are working on this problem along with several other teams comprising of academic groups of world class researchers in this specific area.


There is a huge variety of tasks that come with working on this kind of problem. In the current phase of the program, all of the teams are tasked to each build a system that can process videos in real time on a constrained set of hardware. The smaller, individual tasks can range from trying to effectively collaborate with the other groups, to more technical problems like developing and deploying systems that can run within the set of requirements and getting good performance on a sequestered dataset.
For me personally, I tend to wear several different hats for my team. First and foremost, I am the lead developer of our system and in charge of submitting it to a leaderboard to run on the sequestered dataset (the leaderboard is an online ranking that allows code submissions to evaluate your system on private data). However, I am also in charge of an open source project coming out of the work done for DIVA, managing our servers for training models and testing our system, and building tools for my team to make it easier to do research among other responsibilities.
Activity Detection System

When I joined my team, our system was an amalgam of several components that my team had developed, but there was no underlying architecture of how they were pieced together. Each component processed inputs in batch, and then saved a set of corresponding outputs to files. This meant that each component had to run through an entire video before the next component could start working on it. For example, looking at the figure above, in the previous version of our system, the Mask-RCNN object detections would have to be run for all of the frames in a video before the SORT Object Tracker could start processing them.
When we started Phase 2 of the program, the real time and system submission requirements came into effect. Previously, we just submitted results that we generated to a leaderboard, so our system could be run in several components, and let us change one component and then run results. Now we had to make a system that for one, could run end to end, but also could meet these real time requirements and conformed to an API provided by the government. Because of these requirements, I decided on a Pub/Sub architecture using Apache Kafka as the backbone. You can see a diagram below:
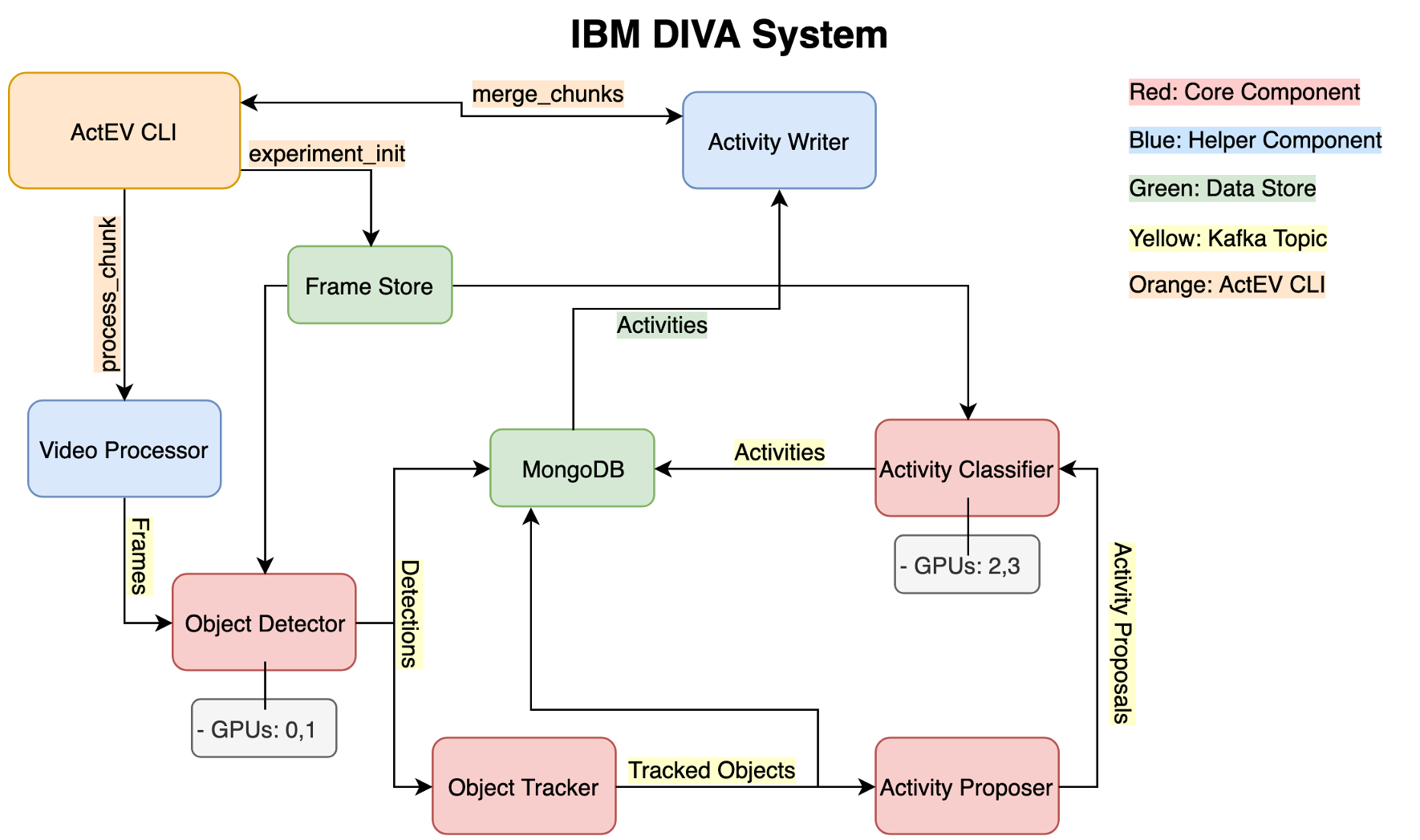
This allowed us to keep the modularity of our system, while enabling these components to run in parallel, since as soon as a component has any output, it can send it to the next component over Kafka. This also allows for a listener to consume the data coming out of each component to store in a database for analysis of the intermediate data streams.
Developing System Components
When developing components for the system, a lot of time and attention needs to be taken to make sure they are working properly and as expected, but also not effecting other parts of your system. This process involves several steps. First, I have to take a research idea that my team or I develop and refactor it into a working component that can be easily integrated into our system. For anyone that has worked with a research codebase, you probably know the pain of taking essentially a prototype and getting it to work with the rest of complex system, making it maintainable for the future, and getting it to run efficiently.
To do this, I first try to pull out the meat of what the component is trying to accomplish. A lot of the times in research code, there isn’t much attention paid to software architectural decisions and how they might affect its use in a broader context. So being able to effectively understand and dissect the core idea out of the rest of a prototype is a valuable skill when working on an applied research project like DIVA.
Once I have the core code separated out, and I’ve explicitly defined the inputs, outputs and dependencies for the component, I wrap it in code that lets it easily be plugged into the system. In the next post, I’ll go more into the details of the open source SDK that I’ve developed to make this really simple.
Next Time
In the next post in this series, I’m going to go more into the open source work that I’ve been able to work on ( Frater) as well as the research I’ve done. I’ll also talk about some of the lessons I’ve learned along the way while working on these different projects.
References
CVPR 2019: http://cvpr2019.thecvf.com/
DIVA: https://www.iarpa.gov/index.php/research-programs/diva
Mask-RCNN: https://arxiv.org/abs/1703.06870
SORT Object Tracking: https://arxiv.org/abs/1602.00763
DIVA Leaderboard: https://actev.nist.gov/sdl
Apache Kafka: https://kafka.apache.org/
Originally Posted on Medium: https://link.medium.com/SvyJx0bRf8
John Henning
Deep Learning Engineer
My interests lie in solving problems at the intersection of research and engineering. I love doing research and then taking it to apply to a problem at hand.